TLDR. DriftQL combines a drift-based behavioral regularizer with critic-driven policy improvement step to introduce a new state of the art that requires no iterative denoising, solvers, and distillation.
Imagine you want to learn to drive, but only by watching dashcam clips and a sparse reward signal. That's (roughly) offline reinforcement learning: improve a policy from fixed data, no exploration allowed.
But what's the catch? If your policy invents an action nobody in the dataset ever tried, you have no way of knowing whether it's brilliant or catastrophic. Modern methods stay safe by carefully modeling what actions appear in the data and keeping the policy close to that. Diffusion and flow policies do this beautifully, but every new action costs a denoising chain, an ODE solver, or a distilled shortcut.
DriftQL takes a simpler path. It learns a drift field: at every point in training, a single vector, shaped by two forces, that chases the data distribution without collapsing onto a single mode. These forces are:
The critic adds the missing ingredient by tilting the objective toward higher-value actions. So drift keeps things in-distribution; value picks the good parts of it.
The result is one forward pass to generate an action. No denoising chain, no ODE solver, no distillation network. And when the data gets noisy (imagine half those dashcam clips were filmed by bad drivers), DriftQL barely loses ground while diffusion and flow methods stumble.
For each dataset state, the actor samples several candidate actions. A single-positive attraction pulls them toward the dataset action, while sample repulsion keeps the candidates from collapsing. The actor is then updated with both the drift loss and the critic objective.
DriftQL uses a stochastic actor \(a = f_\theta(s, \epsilon)\). For each state, the actor produces \(N\) candidate actions \(\hat{a}_i\), and the drift field gives each candidate a one-step training target.
Offline RL supplies one dataset action \(a^+\) for the sampled state, so the attraction term is a direct pull to that action:
The other generated actions estimate the current policy distribution and produce a repulsive correction:
The net drift combines support preservation with diversity. The actor minimizes this drift loss together with a critic-driven improvement term:
At test time, DriftQL samples an action with one actor forward pass. There is no denoising chain, ODE solver, or distillation network.
And that is the whole recipe. One network, one loss, one feedforward call. The attraction and repulsion keep the policy faithful to the data, the critic steers it toward the parts that pay off, and the heavy machinery of denoising chains, ODE solvers, and distillation networks simply falls away.
A step-by-step visual walkthrough
Draw target and base distributions, then watch the drift policy transport samples
We evaluate DriftQL on D4RL and OGBench, covering locomotion, navigation, manipulation, multimodal behavior, and sparse-reward long-horizon tasks. We compare against Gaussian-policy methods (BC, IQL, ReBRAC), diffusion policies (IDQL, SRPO, CAC), and flow policies (FAWAC, FBRAC, IFQL, FQL).
AntMaze
HumanoidMaze
AntSoccer
Cube
Scene
Puzzle
Pen
Door
Hammer
Relocate
Environment media adapted from OGBench and Minari.
Training and evaluation
DriftQL is trained for 1M gradient steps on state-based OGBench tasks and 500K steps on D4RL tasks, with evaluation every 100K steps. OGBench reports the average over the last three checkpoints; D4RL reports the final checkpoint. Results are averaged over 8 seeds.
Environment-level averages are shown below. OGBench uses success rates, and D4RL uses normalized scores.
| Gaussian | Diffusion | Flow | Drift | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Task | BC | IQL | ReBRAC | IDQL | SRPO | CAC | FAWAC | FBRAC | IFQL | FQL | DriftQL |
| D4RL | |||||||||||
| antmaze (6) | 17 | 57 | 78 | 79 | 74 | 30 ± 3 | 44 ± 3 | 64 ± 7 | 65 ± 7 | 84 ± 3 | 84 ± 9 |
| adroit (12) | 48 | 53 | 59 | 52 ± 1 | 51 ± 1 | 43 ± 2 | 48 ± 1 | 50 ± 2 | 52 ± 1 | 52 ± 1 | 50 ± 5 |
| locomotion (9) | 50 | 82 | 90 | 82 | 87 | - | - | - | 50 ± 3 | 63 ± 2 | 81 ± 23 |
| D4RL Overall | 38 | 64 | 76 | 71 ± 1 | 71 ± 1 | - | - | - | 56 ± 9 | 66 ± 1 | 72 ± 2 |
| OGBench | |||||||||||
| antmaze-large-st (5) | 11 ± 1 | 53 ± 3 | 81 ± 5 | 21 ± 5 | 11 ± 4 | 33 ± 4 | 6 ± 1 | 60 ± 6 | 28 ± 5 | 79 ± 3 | 92 ± 4 |
| antmaze-giant-st (5) | 0 ± 0 | 4 ± 1 | 26 ± 8 | 0 ± 0 | 0 ± 0 | 0 ± 0 | 0 ± 0 | 4 ± 4 | 3 ± 2 | 9 ± 6 | 60 ± 2 |
| humanoidmaze-med-st (5) | 2 ± 1 | 33 ± 2 | 22 ± 8 | 1 ± 0 | 1 ± 1 | 53 ± 8 | 19 ± 1 | 38 ± 5 | 60 ± 1 | 58 ± 5 | 62 ± 2 |
| humanoidmaze-large-st (5) | 1 ± 0 | 2 ± 1 | 2 ± 1 | 1 ± 0 | 0 ± 0 | 0 ± 0 | 0 ± 0 | 2 ± 0 | 11 ± 2 | 4 ± 2 | 5 ± 8 |
| antsoccer-arena-st (5) | 1 ± 0 | 8 ± 2 | 0 ± 0 | 12 ± 4 | 1 ± 0 | 2 ± 4 | 12 ± 0 | 16 ± 1 | 33 ± 6 | 60 ± 2 | 65 ± 2 |
| cube-single-st (5) | 5 ± 1 | 83 ± 3 | 91 ± 2 | 95 ± 2 | 80 ± 5 | 85 ± 9 | 81 ± 4 | 79 ± 7 | 79 ± 2 | 96 ± 1 | 94 ± 3 |
| cube-double-st (5) | 2 ± 1 | 7 ± 1 | 12 ± 1 | 15 ± 6 | 2 ± 1 | 6 ± 2 | 5 ± 2 | 15 ± 3 | 14 ± 3 | 29 ± 2 | 25 ± 2 |
| scene-st (5) | 5 ± 1 | 28 ± 1 | 41 ± 3 | 46 ± 3 | 20 ± 1 | 40 ± 7 | 30 ± 3 | 45 ± 5 | 30 ± 3 | 56 ± 2 | 74 ± 4 |
| puzzle-3x3-st (5) | 2 ± 0 | 9 ± 1 | 21 ± 1 | 10 ± 2 | 18 ± 1 | 19 ± 0 | 6 ± 2 | 14 ± 4 | 19 ± 1 | 30 ± 1 | 35 ± 3 |
| puzzle-4x4-st (5) | 0 ± 0 | 7 ± 1 | 14 ± 1 | 29 ± 3 | 10 ± 3 | 15 ± 3 | 1 ± 0 | 13 ± 1 | 25 ± 5 | 17 ± 2 | 27 ± 3 |
| OGBench Overall | 3 ± 0 | 23 ± 1 | 31 ± 1 | 23 ± 1 | 14 ± 1 | 25 ± 2 | 16 ± 1 | 29 ± 1 | 30 ± 1 | 44 ± 1 | 54 ± 1 |
Values at or above 95% of the best performance in each row are bolded. Standard deviations are shown after ± where available.
Robustness under corrupted offline data
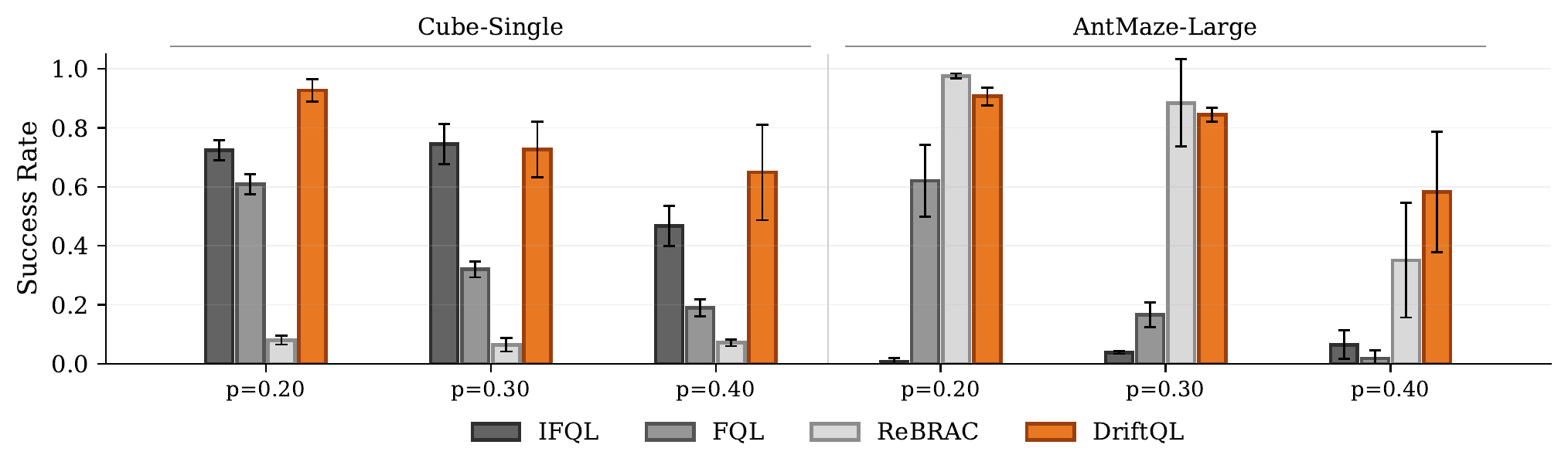
We corrupt the default OGBench cube-single and antmaze-large datasets by replacing a fraction of actions with uniformly random actions, then average success over the 800k, 900k, and 1M checkpoints. DriftQL stays strong as random-action corruption increases from p = 0.20 to p = 0.40. On Cube, it is strongest at every corruption level. On AntMaze, it degrades more gracefully and becomes strongest at p = 0.40.
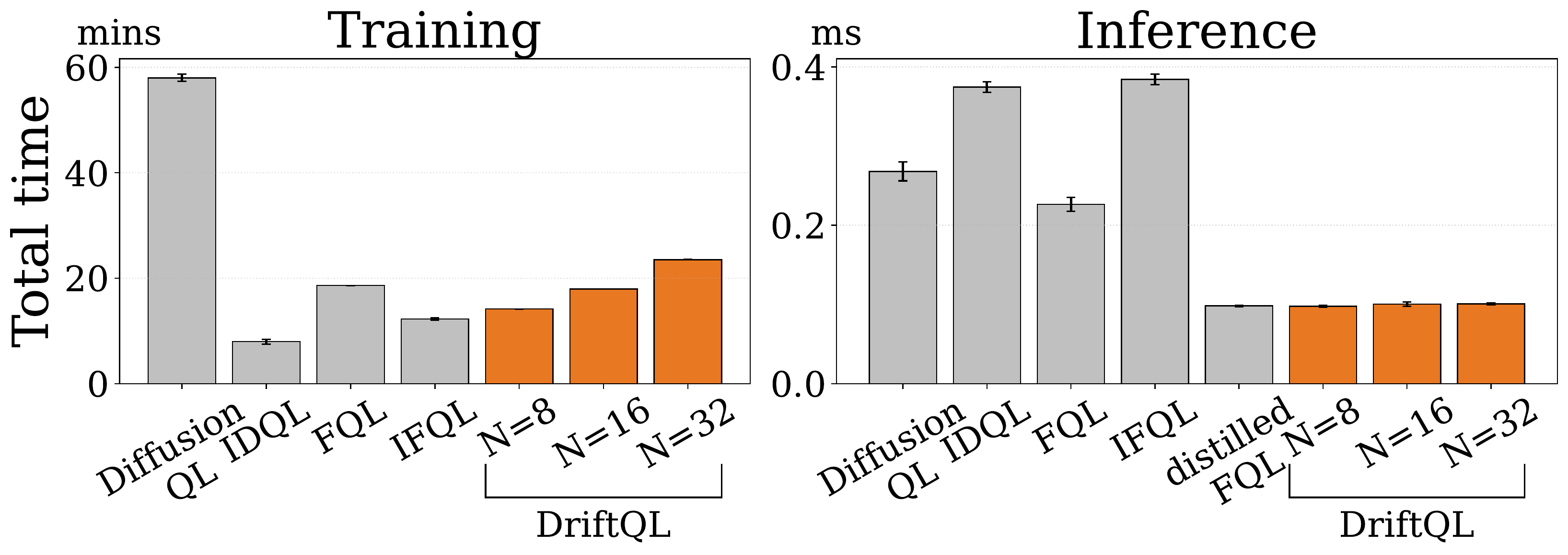
Computational efficiency and inference latency
DriftQL acts in one feedforward pass. It avoids denoising chains, ODE solvers, and distillation while matching the latency profile of one-step policies.
| Method | Sequential NFEs | Distillation required |
|---|---|---|
| Diffusion-QL | K x Nc | No |
| IDQL | K x Nc | No |
| FQL | 5-20 (ODE) + 1 (distilled) | Yes |
| IFQL | K x Nc | No |
| DriftQL | 1 (feedforward) | No |
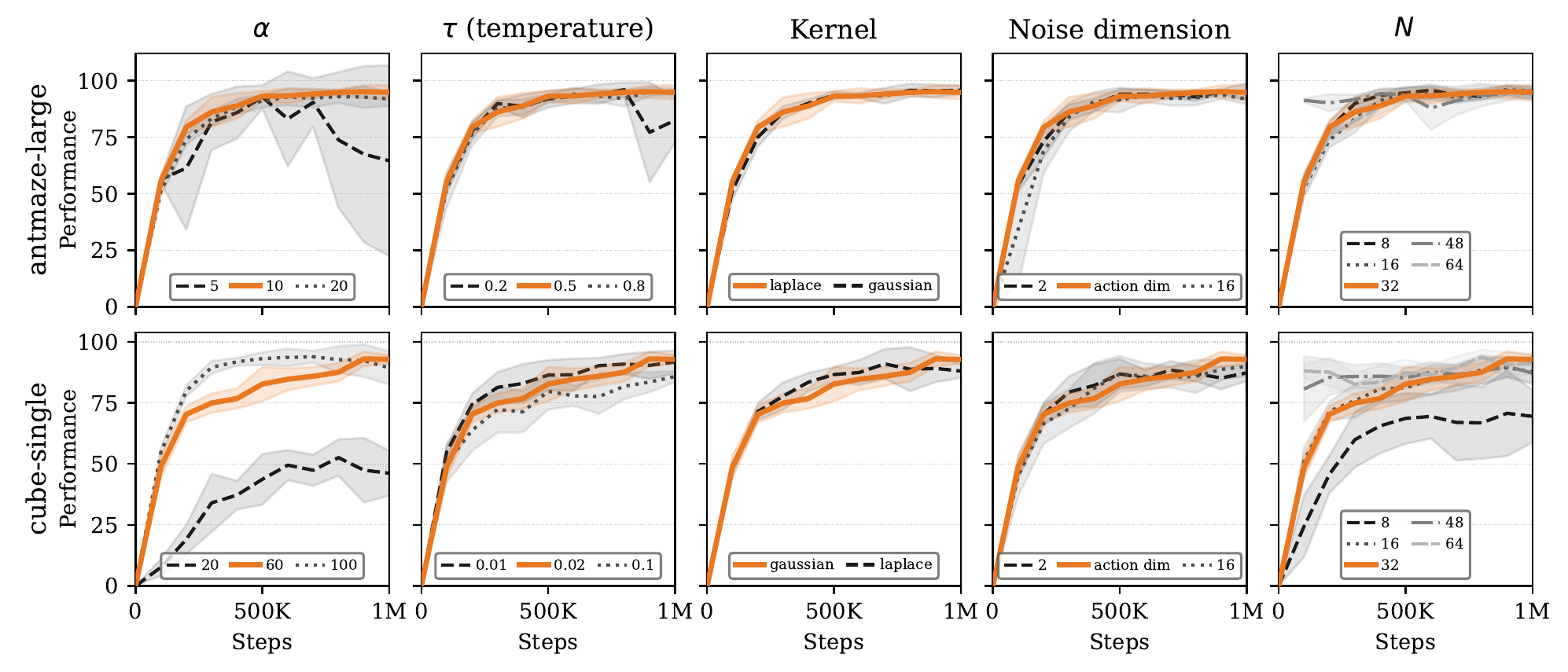
Ablation study
We ablate the main DriftQL hyperparameters on antmaze-large-navigate and cube-single-play, changing one setting at a time relative to the tuned defaults.
Taken together, the picture is consistent. DriftQL matches or beats diffusion and flow policies across D4RL and OGBench, holds its ground when the offline data is corrupted, and does it all in a single feedforward pass. Simpler at inference, sturdier under noise, and stronger on the benchmarks that actually stress a policy.
@article{houssaini2026drift,
title={Drift Q-Learning},
author={Houssaini, Anas and Danesh, Mohamad H and Abyaneh, Amin and Fujimoto, Scott and Lin, Hsiu-Chin and Meger, David},
journal={arXiv preprint arXiv:2606.00350},
year={2026}
}